服务器
ESP32
ubuntu
typescript
高数
Java开发
制图表达
pat考试
模板
端口映射
求职招聘
visualstudio
安卓
计算机软件考试
研究报告
天气App
i18next
计算机考博
服务容错
PLC远程上下载
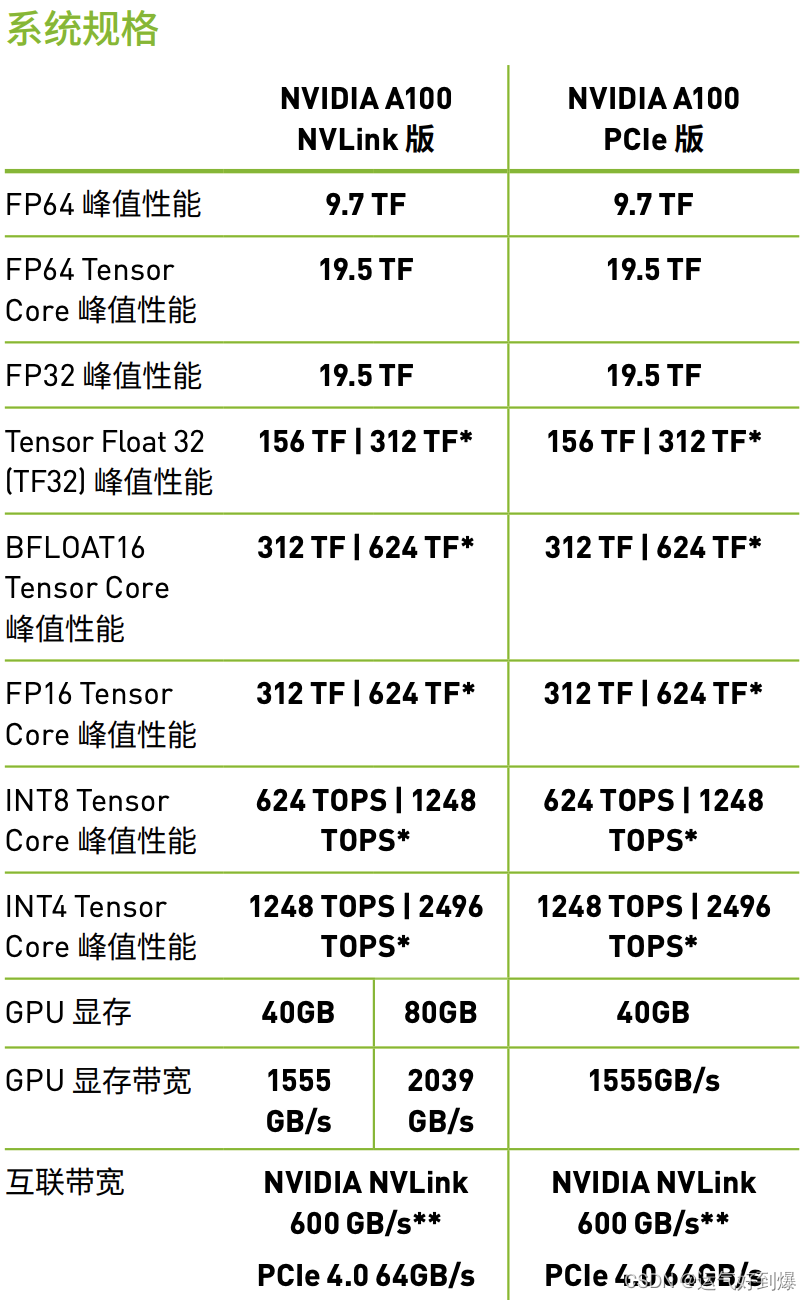
gpu算力
2024/4/13 11:15:50
NPU、CPU、GPU算力及算力计算方式
NVIDIA在9月20日发布的NVIDIA DRIVE Thor 新一代集中式车载计算平台,可在单个安全、可靠的系统上运行高级驾驶员辅助应用和车载信息娱乐应用。提供 2000 万亿次浮点运算性能(2000 万亿次8位浮点运算)。NVIDIA当代产品是Orin,算力是…

【AI底层逻辑】——篇章7(上):海量运算背后的算力支持
目录
引入
一、计算机芯片
1、芯片的制造
2、复杂指令集&精简指令集
3、并行计算的GPU
二、协作计算
1、分布式技术“三论文”
2、不可兼得的CAP定理
3、故障类型
续下篇...
往期精彩: 引入
早在2016年DeepMind就公布了AlphaGo的算法细节࿰…

『heqingchun-ubuntu系统下安装cuda与cudnn』
ubuntu系统下安装cuda与cudnn
一、安装依赖
1.更新
sudo apt updatesudo apt upgrade -y2.基础工具
sudo apt install -y build-essential python二、安装CUDA
1.文件下载
网址
https://developer.nvidia.com/cuda-toolkit-archive依次点击
(1)“CUDA Toolkit 11.6.2”…

笔记:如何用趋动云GPU线上跑AI项目实践-部署DragGan模型
1.创建项目
1)进入趋动云用户工作台,在当前空间处选择注册时系统自动生成的空间(其他空间无免费算力);
2)点击 快速创建,选择 创建项目,创建新项目;
3)填写…
![[问题解决] no CUDA-capable device is detected](https://img-blog.csdnimg.cn/direct/73575b08c03b499496f8ae596397bb33.png)
[问题解决] no CUDA-capable device is detected
先说环境,在docker下的gpu环境ffmpeg,然后今天突然无法使用,使用时出现如下图所示: 看着报错大致内容是找不到设备,网上寻找一番没有有用的东西,于是决定自己解决,仔细察看一番后,猜…
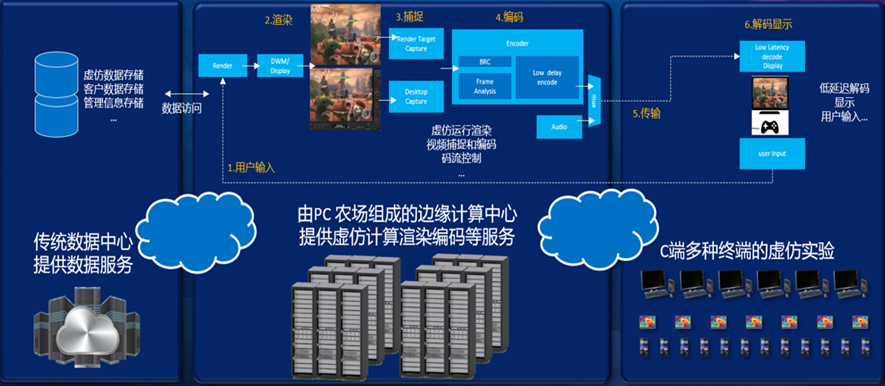
客户案例 | 思腾合力GPU算力节点助力实时云渲染
客户介绍 平行云是国内领先的云化XR概念倡导者与技术先行者,LarkXR是平行云研发的云化XR PaaS平台。LarkXR能够帮助XR领域企业级客户快速实现技术、产品及平台的云化转型,高效使能企业的云化XR业务,有效保护客户的内容安全,让多种…
在 Android 上部署预训练模型
更多 TVM 中文文档可访问 →https://tvm.hyper.ai/docs
下面是用 Relay 编译 Keras 模型,并将其部署到 Android 设备上的示例:
import os
import numpy as np
from PIL import Image
import keras
from keras.applications.mobilenet_v2 import Mobile…
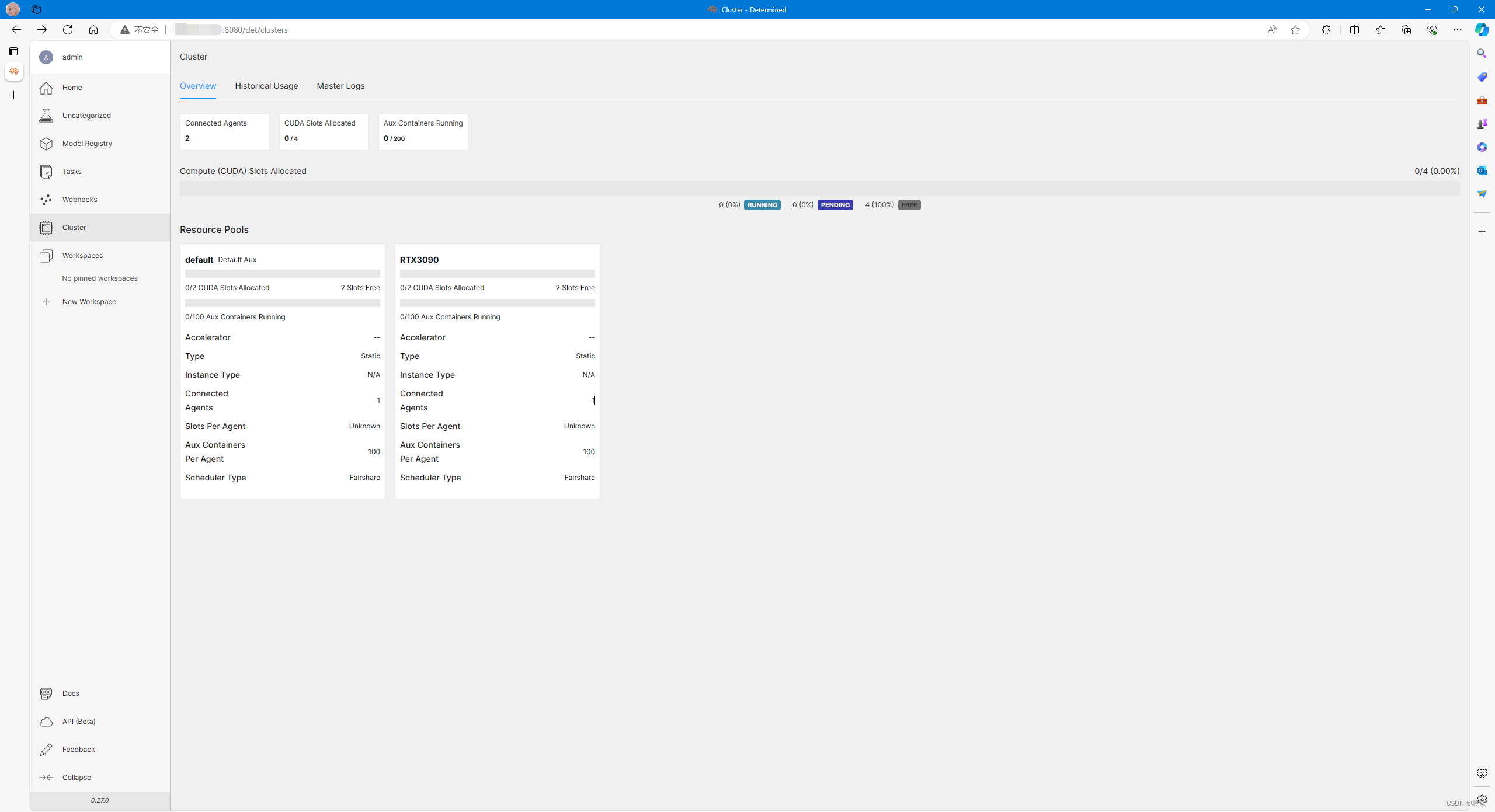
GPU算力池管理工具Determined AI部署与使用教程(2024.03)
1. 概念
1.1 什么是Determined?
Determined AI 是一个全功能的深度学习平台,兼容 PyTorch 和 TensorFlow。它主要负责以下几个方面:
分布式训练:Determined AI 可以将训练工作负载分布在多个 GPU(可能在多台计算机上…
记使用JSoup来爬取NVIDIA GPU列表
1、倒入Jsoup依赖 <dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.2</version></dependency>2、上代码
package ai.dekube.clustermonitor.server.service;import ai.dekube.cluster…

一文详解多模态大模型发展及高频因子计算加速GPU算力 | 英伟达显卡被限,华为如何力挽狂澜?
★深度学习、机器学习、多模态大模型、深度神经网络、高频因子计算、GPT-4、预训练语言模型、Transformer、ChatGPT、GenAI、L40S、A100、H100、A800、H800、华为、GPU、CPU、英伟达、NVIDIA、卷积神经网络、Stable Diffusion、Midjourney、Faster R-CNN、CNN 随着人工智能技术…

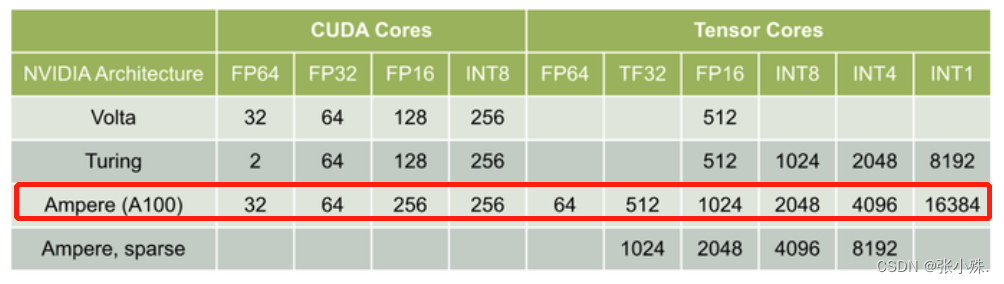
【架构】GPU架构总结
文章目录 GPU架构GPU渲染内存架构Streaming Multiprocessor(SM)CUDA CoreTensor CoreRT CoreCPU-GPU异构系统GPU资源管理模型 GPU架构演进G80 架构Fermi 架构Maxwell架构Tesla架构Pascal架构Volta 架构Turing架构Ampere 架构Hopper架构 参考文献 GPU架构
主要组成包括…

吴恩达深度学习环境本地化构建wsl+docker+tensorflow+cuda
Tensorflow2 on wsl using cuda 动机环境选择安装步骤1. WSL安装2. docker安装2.1 配置Docker Desktop2.2 WSL上的docker使用2.3 Docker Destop的登陆2.4 测试一下 3. 在WSL上安装CUDA3.1 Software list needed3.2 [CUDA Support for WSL 2](https://docs.nvidia.com/cuda/wsl-…
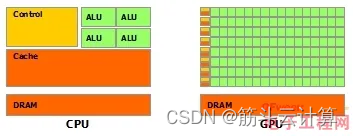
CPU vs. GPU :本质差异是?
他们的目的都是做并行计算的,但并行计算可分为时间上的并行和空间上的并行。所以我觉得本质差异是:
CPU 时间并行GPU 空间并行 这样就容易理解他们的工作方式:
对CPU来说,不同的核心可以执行不同的机器指令但GPU则不同ÿ…
Lichee Pi 4A:RISC-V架构的开源硬件之旅
一、简介 Lichee Pi 4A是一款基于RISC-V指令集的强大Linux开发板,它凭借出色的性能和丰富的接口,吸引了众多开发者和爱好者的关注。这款开发板不仅适用于学习和研究RISC-V架构,还可以作为软路由、小型服务器或物联网设备的核心组件。 目录
一…

GPU密集型计算性能优化的方法和技术
对GPU密集型计算进行性能优化的方法和技术多种多样。通过一些优化策略和技术需要综合考虑应用程序的具体需求、所使用的GPU硬件、以及编程模型和库的选择。通过不断地分析和调整,可以实现GPU计算性能的持续提升。以下是一些常用的优化策略和技术: 算法优…

云卷云舒:算力网络+云原生(中):探索构建算力网络数据库
一、导言
1、基础要求:算力网络时代,数据类型、范围充分延展和爆发,数据库也要适应起来,分布式数据库是起步要求;
2、近期需求:通过云服务的方式提供算网时代,尤其是智能大模型所需要的向量数…

会议剪影 | 思腾合力受邀出席第四届长三角文博会并作主题演讲
以“担当新使命:长三角文化产业的力量”为主题的「第四届长三角国际文化产业博览会」于2023年11月16日-19日在国家会展中心(上海)成功举办。思腾合力作为行业领先的人工智能基础架构解决方案商出席本次盛会。 此次展会的面积首次超过10万平米,…

存内计算引领新一代技术革新,开启算力新时代
文章目录
存内计算与传统计算的区别
存内计算与传统计算的区别
存内计算芯片的优势
存内计算在各个领域的应用
存内计算技术对未来发展的影响
CSDN存内计算开发者社区:引领新一代技术革新的最前沿
社区内容专业度
社区具备的资源
社区的开放性
社区招募令…

如何评估计算机的算力:从 CPU 到 GPU 的演变
计算机的算力一直是科学技术发展的重要驱动力之一。从最早的计算机到现代的超级计算机,计算机的算力不断提高,为人类社会带来了前所未有的变革。其中,CPU(中央处理器)和 GPU(图形处理器)是计算机…

未来每家公司都需要有自己的大模型- Hugging Face创始人分享
自ChatGPT发布以来,有人称其是统治性一切的模型。Hugging Face创始人兼首席执行官Clem Delangue介绍,Hugging Face平台已经有15000家公司分享了25万个开源模型,当然这些公司不会为了训练模型而训练模型,因为训练模型需要投入大量资…
【GPU驱动开发】-Mesa ST和GLSL编译器衔接交互分析
前言
不必害怕未知,无需恐惧犯错,做一个Creator!
(基于Mesa 22.2.5版本)
Mesa State Tracker 与 GLSL 编译器的协同工作是 Mesa 3D 图形渲染管线中的关键环节。这两者的衔接确保了 OpenGL API 调用能够正确、高效地…

思腾云计算中心 | 5千平米超大空间,基础设施完善,提供裸金属GPU算力租赁业务
2021年,思腾合力全资收购包头市易慧信息科技有限公司,正式开启云计算业务。思腾云计算中心占地2400平米,位于包头市稀土高新区,毗邻多家知名企业,地理位置优越,交通便利,是区内重要的信息化产业…
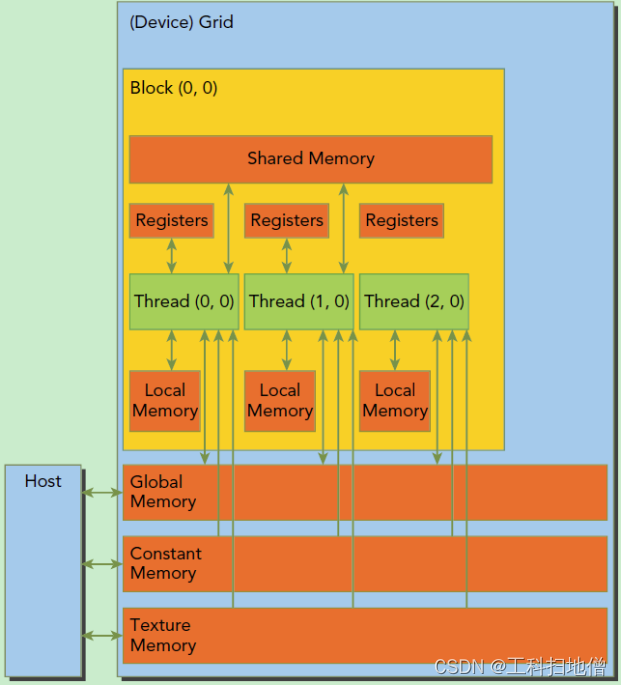
GPU 基础知识整理
萌新:
在接触一款硬件时我会:基础硬件结构,线程结构,内存布局,数据吞吐量,等方面进行学习
首先GPU的特点: 并行性能:GPU 是专门设计用于并行计算的硬件,通常具有大量的处理单元&am…
用HTML+JS制作二维码生成器
代码如下 <!DOCTYPE html> <html> <head> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <title>二维码生成</title> <style> body { font-family: Arial, sans-serif; …

3 分钟看完 NVIDIA GPU 架构及演进
近期随着 AI 市场的爆发式增长,作为 AI 背后技术的核心之一 GPU(图形处理器)的价格也水涨船高。GPU 在人工智能中发挥着巨大的重要,特别是在计算和数据处理方面。目前生产 GPU 主流厂商其实并不多,主要就是 NVIDIA、AM…

TensorFlow训练大模型做AI绘图,需要多少的GPU算力支撑
TensorFlow训练大模型做AI绘图,需要多少的GPU算力支撑!这个问题就涉及到了资金投资的额度了。众所周知,现在京东里面一个英伟达的显卡,按照RTX3090(24G显存-涡轮风扇)版本报价是7000-7500之间。如果你买一张这样的单卡…

Chart 5 性能优化概述
文章目录 前言5.1 可移植性5.2 优化梗概5.3 OpenCL 移植的初始评估5.4 将CPU代码移植到OpenCL GPU5.5 并行化GPU和CPU工作负载5.6 瓶颈分析5.6.1 识别瓶颈5.6.2 解决瓶颈 5.7 API层面性能优化5.7.1 API函数调用的正确安排5.7.2 使用基于事件驱动的pipeline5.7.3 内核编译和构建…
思腾云计算中心 | ,基础设施完善,提供裸金属GPU算力租赁业务
2021年,思腾合力全资收购包头市易慧信息科技有限公司,正式开启云计算业务。思腾云计算中心占地2400平米,位于包头市稀土高新区,毗邻多家知名企业,地理位置优越,交通便利,是区内重要的信息化产业…

2023我和云栖有个约会
时间:2023.11.1
地点:云栖小镇
事件:约会 昨天刚在网上看到了有阿姨在云栖大会给自己女儿相亲的照片,今天直接就赶了过去。约会了一整天,虽然很累,但真的很值得。由于是第一次和云栖约会,那就…

智能交通技术与数据集大观:揭秘趋动云的无尽能量,引领AI发展的GPU算力及相关资源
智能交通是一种先进的交通系统,其核心目标在于通过实时数据的采集、分析以及智能决策,全面提升城市交通的效率、安全性和便捷性。该系统涵盖多项关键技术,包括行人检测、车辆检测、智能交通信号控制、智能导航和路径规划、以及安全监控等。 行…
在国产GPU寒武纪MLU上快速上手Pytorch使用指南
本文旨在帮助Pytorch使用者快速上手使用寒武纪MLU。以代码块为主,文字尽可能简洁,许多部分对标NVIDIA CUDA。不正确的地方请留言更正。本文不定期更新。 文章目录 前言Cambricon PyTorch的Python包torch_mlu导入将模型加载到MLU上model.to(mlu)定义损失函…
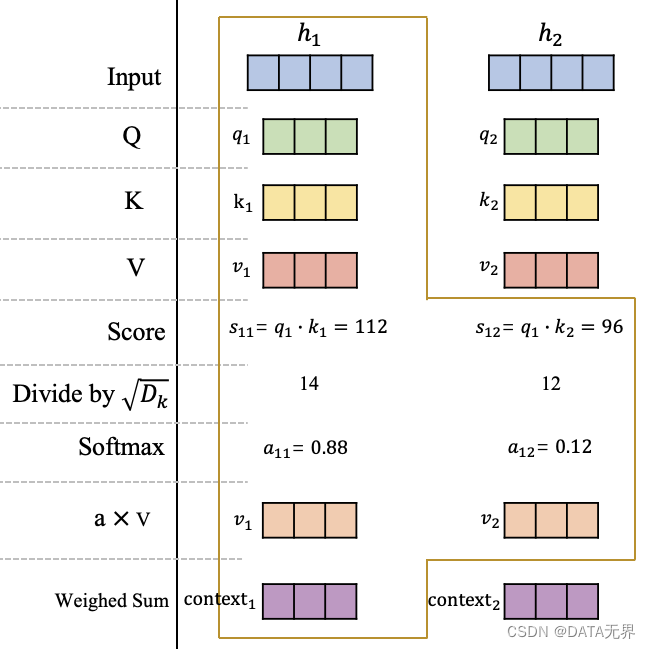
AI大语言模型学习笔记之三:协同深度学习的黑魔法 - GPU与Transformer模型
Transformer模型的崛起标志着人类在自然语言处理(NLP)和其他序列建模任务中取得了显著的突破性进展,而这一成就离不开GPU(图形处理单元)在深度学习中的高效率协同计算和处理。
Transformer模型是由Vaswani等人在2017年…
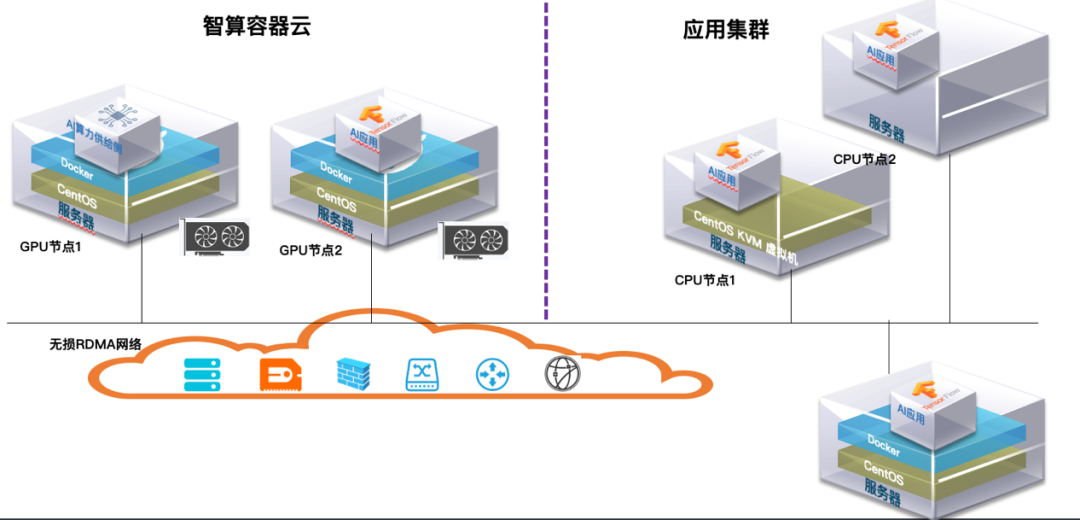
云原生演进中的AI算力高效使用
0 1 云原生技术的普及与发展
云原生技术是一种基于容器技术的轻量级、高可用的应用架构,具有弹性扩展、快速部署、统一管理等特点。随着企业对敏捷开发和快速迭代的需求不断增加,云原生技术的普及与发展已成为不可逆转的趋势。
图1. 云原生技术发展之路…

会议邀请 | 思腾合力邀您共赴第二十五届高交会(CHTF2023)
2023年11月15-19日,以“激发创新活力 提升发展质量”为主题的「第二十五届中国国际高新技术成果交易会(CHTF2023)」将在深圳会展中心(福田)和深圳国际会展中心(宝安)举办。思腾合力作为行业领先…
WSL2安装Ubuntu,配置机器学习环境
文章目录 1.WSL2安装Ubuntu,更改安装位置,作为开发环境供vscode和pycharm使用:2.更换国内源:3.安装图形界面:4.安装cudacudnntorch5.安装opencv6.调用摄像头7.使用yolov8测试 WSL全称Windows Subsystem for Linux&…
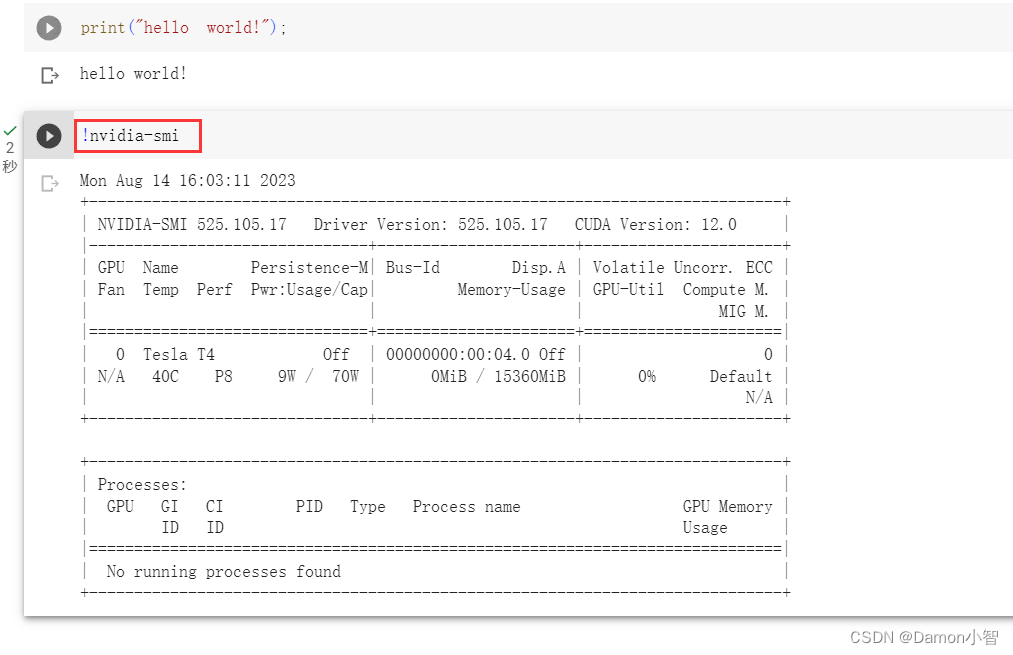
深度学习-搭建Colab环境
Google Colab(Colaboratory) 是一个免费的云端环境,旨在帮助开发者和研究人员轻松进行机器学习和数据科学工作。它提供了许多优势,使得编写、执行和共享代码变得更加简单和高效。Colab 在云端提供了预配置的环境,可以直接开始编写代码&#x…
VNIDIA 显卡相关 Note book
NVIDIA 站点参考:
1. CUDA 12.3 Update 1 Release Notes — Release Notes 12.3 documentation ubuntu 系统版本: lsb_release -a python 验证:
import torch
print(torch.version.cuda) 查看相关 nvidia-smi ubuntu-drivers devices 查看…

空间计算时代催生新一波巨大算力市场需求
什么是空间计算? 空间计算是一种整合虚拟现实(VR)、增强现实(AR)、混合现实(MR)等技术的计算模式,旨在将数字信息与真实世界融合在一起。这种融合创造了一个全新的计算环境ÿ…
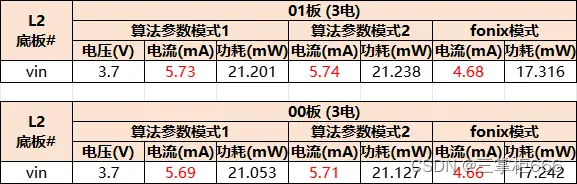
存内计算技术打破常规算力局限性
目录
前言
关于存内计算
1、常规算力局限性
2、存内计算诞生记
3、存内计算核心
存内计算芯片研发历程及商业化
1、存内计算芯片研发历程
2、存内计算先驱出道
3、存内计算商业化落地
基于知存科技存内计算开发板ZT1的降噪验证
(一)任务目标以…
CVPR 2023 精选论文学习笔记:Towards Scalable Neural Representation for Diverse Videos
基于 MECE 原则,我们给出以下四个分类标准:
分类标准 1:表示类型
隐式神经表示(INR)
隐式神经表示(INR)是一类神经网络架构,将场景或对象表示为从 3D 点映射到颜色和不透明度值的连续函数。该函数通常从一组训练图像或视频中学习,然后可以用于渲染场景或对象的新视…

Renderbus瑞云渲染现在支持3dsMax 2024了
Autodesk于今年3月份发布了最新版本的3ds Max软件,其中包含令人兴奋的新功能和增强功能。3ds Max 2024渲染功能暂时可与V-Ray 6.1.2和corona 10配合使用,直至更多渲染引擎发布更新。而您现在可以在Renderbus瑞云渲染平台使用最新版本的3ds Max 2024。
关…
NVIDIA cuda安装时全部失败
查看了很多博客,有写的非常详细清楚的博客,csdn上真的是一个很好的学习平台,我在学习过程中遇到的好多bug,都能在这上面找到解决方法,就是一个老师的存在。
我安装NVIDIA cuda安装时失败了N次,数不清了&am…
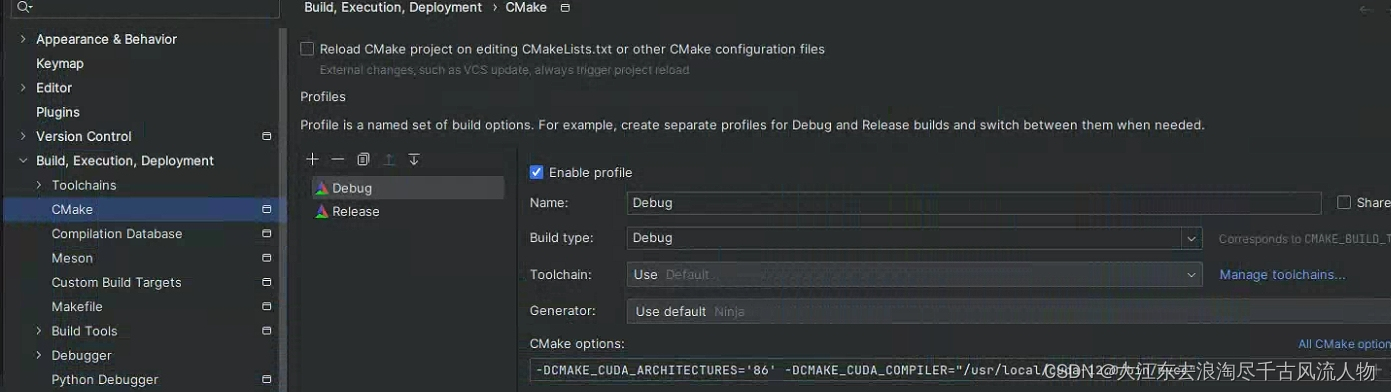
CMAKE_CUDA_ARCHITECTURES set to ‘native’多版本与版本号矛盾问题,报错
CMAKE_CUDA_ARCHITECTURES set to ‘native’多版本与版本号矛盾问题,报错 1. 报错提醒如下图2. 原因本地安装多个cuda版本导致native寻找到多个版本,导致报错3. 具体配置需要根据你的显卡型号来确认 1. 报错提醒如下图 2. 原因本地安装多个cuda版本导致…

上海智慧岛大数据云计算中心项目正式封顶!
上海智慧岛大数据云计算中心封顶仪式现场
1月15日,云端股份在上海智慧岛大数据云计算中心举行封顶仪式。云之端网络(江苏)股份有限公司(以下称“云端股份”)总经理贡伟力先生,常务副总张靖先生等公司成员&…
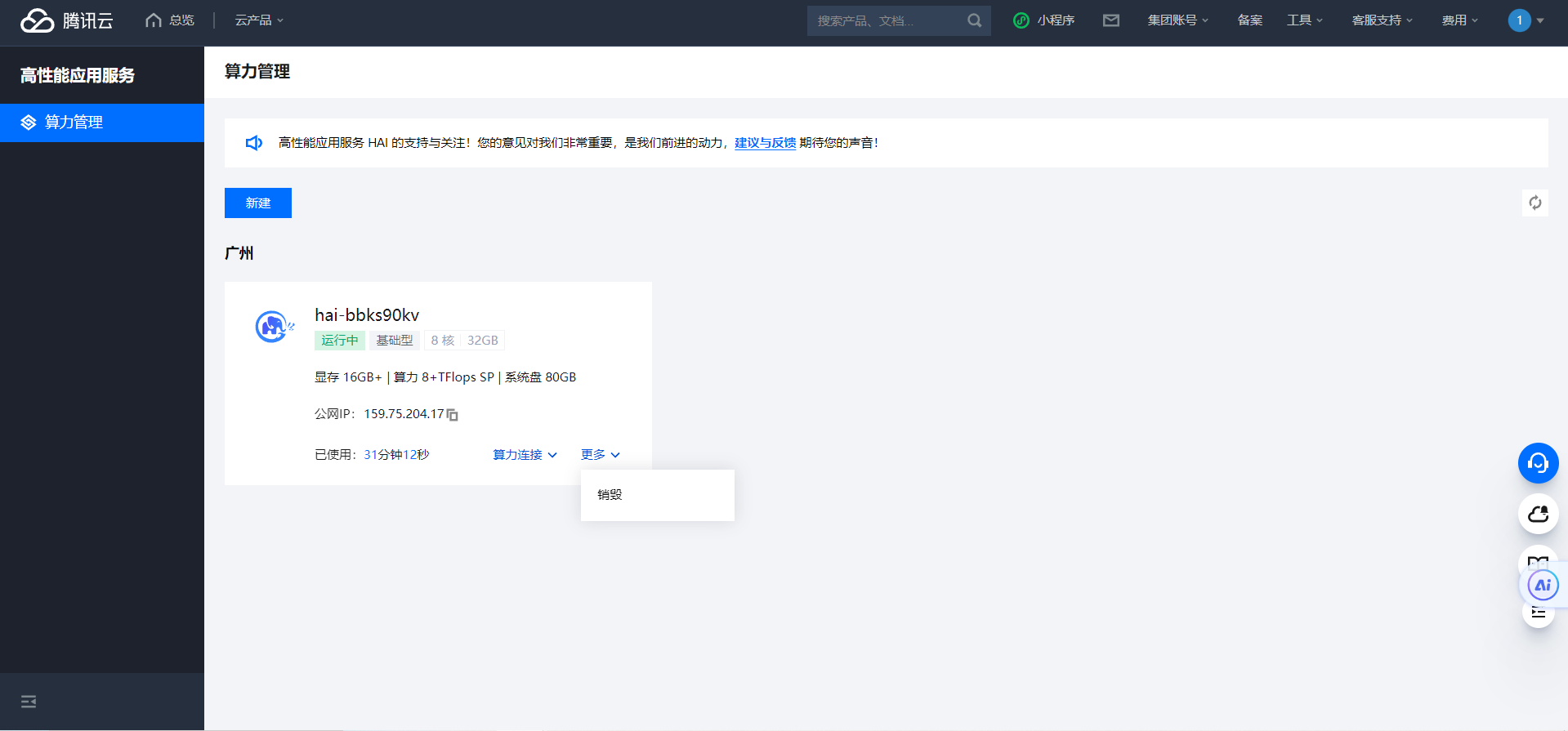
【腾讯云 HAI域探秘】基于高性能应用服务器HAI部署的 ChatGLM2-6B模型,我开发了AI办公助手,公司行政小姐姐用了都说好!
目录
前言 一、腾讯云HAI介绍:
1、即插即用 轻松上手 2、横向对比 青出于蓝
3、多种高性能应用部署场景
二、腾讯云HAI一键部署并使用ChatGLM2-6B快速实现开发者所需的相关API服务
1、登录 高性能应用服务 HAI 控制台
2、点击 新建 选择 AI模型,…

光环云与跨境智算云网实验室联合发布“数据全链路安全与合规解决方案”
1月19日,国际数据经济产业创新大会在上海临港新片区召开,光环云受邀出席。会上,光环云与“上海国际数据港创新实验室——跨境智算云网实验室”联合发布“数据全链路安全与合规解决方案”,助力企业数据跨境流动更加便捷、安全、高效…

CUDA简介, 配置和运行第一个CUDA程序(Windows和Linux)
CUDA简介
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种通用并行计算架构。CUDA允许程序员利用NVIDIA GPU的并行计算能力,加速各种计算密集型应用程序。
CUDA技术基于GPU的并行计算原理。传统的CPU处理器拥有少量的核心&…


【华为OD题库-076】执行时长/GPU算力-Java
题目 为了充分发挥GPU算力,需要尽可能多的将任务交给GPU执行,现在有一个任务数组,数组元素表示在这1秒内新增的任务个数且每秒都有新增任务。 假设GPU最多一次执行n个任务,一次执行耗时1秒,在保证GPU不空闲情况下&…
知识工作者,需要填报工时么? | IDCF
作者:冬哥
来源:DevOps 引 子
“知识工作者,需要填报工时么?”忘记是因为什么,突然想到这个话题。似乎是没什么值得讨论的话题,我们的观点也是旗帜鲜明地认为没有必要,但实际现实中填报工时似…
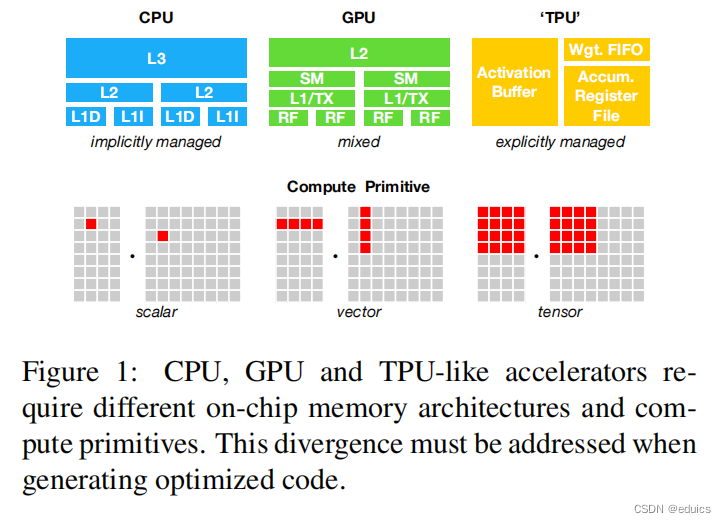
CPU、GPU、TPU内存子系统架构
文章目录 CPU、GPU、TPU内存子系统架构概要CPUGPUTPU共同点和差异: CPU、GPU、TPU内存子系统架构
概要
Memory Subsystem Architecture,图源自TVM
CPU
CPU(中央处理器)的内存子系统:隐式管理
主内存(…

查看电脑cuda版本
1.找到NVODIA控制面板 输入NVIDIA搜索即可 出现NVIDIA控制面板 点击系统信息
2.WINR 输入nvidia-smi 检查了一下,电脑没用过GPU,连驱动都没有 所以,装驱动……
选版本,下载 下载后双击打开安装 重新输入nvidia-smi 显示如下…

好莱坞编剧大罢工终于结束;与OpenAI创始人共进早餐;使用DALL-E 3制作绘本分享;生成式AI的基础设施架构 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 好莱坞编剧大罢工终于结束:简单说就是AI妥协了 https://www.wgacontract2023.org/the-campaign/summary-of-the-2023-wga-…
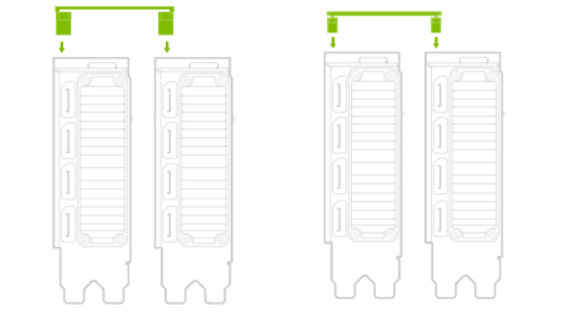
深入了解 GPU 互联技术——NVLINK
随着人工智能和图形处理需求的不断增长,多 GPU 并行计算已成为一种趋势。对于多 GPU 系统而言,一个关键的挑战是如何实现 GPU 之间的高速数据传输和协同工作。然而,传统的 PCIe 总线由于带宽限制和延迟问题,已无法满足 GPU 之间通…

transfomer中Decoder和Encoder的base_layer的源码实现
简介
Encoder和Decoder共同组成transfomer,分别对应图中左右浅绿色框内的部分. Encoder: 目的:将输入的特征图转换为一系列自注意力的输出。 工作原理:首先,通过卷积神经网络(CNN)提取输入图像的特征。然…

北京交通大学高性能作业——多类积分函数华为鲲鹏 CPU 与 CPU + GPU 对比
多类积分函数华为鲲鹏 CPU 与 CPU GPU 对比 1.description of the problem you have chosen2.description of the HUAWEI platform you use (including both software and hardware)3.your algorithm flow chart直接计算流程图OpenMP计算流程图CUDA计算流程图 4.analysis of t…
Determining Which Version of GDS is Installed
Determining Which Version of GDS is Installed
To determine which version of GDS you have, run the following command: $ gdscheck.py -v Example output: GDS release version: 1.0.0.78 nvidia_fs version: 2.7 libcufile version: 2.4
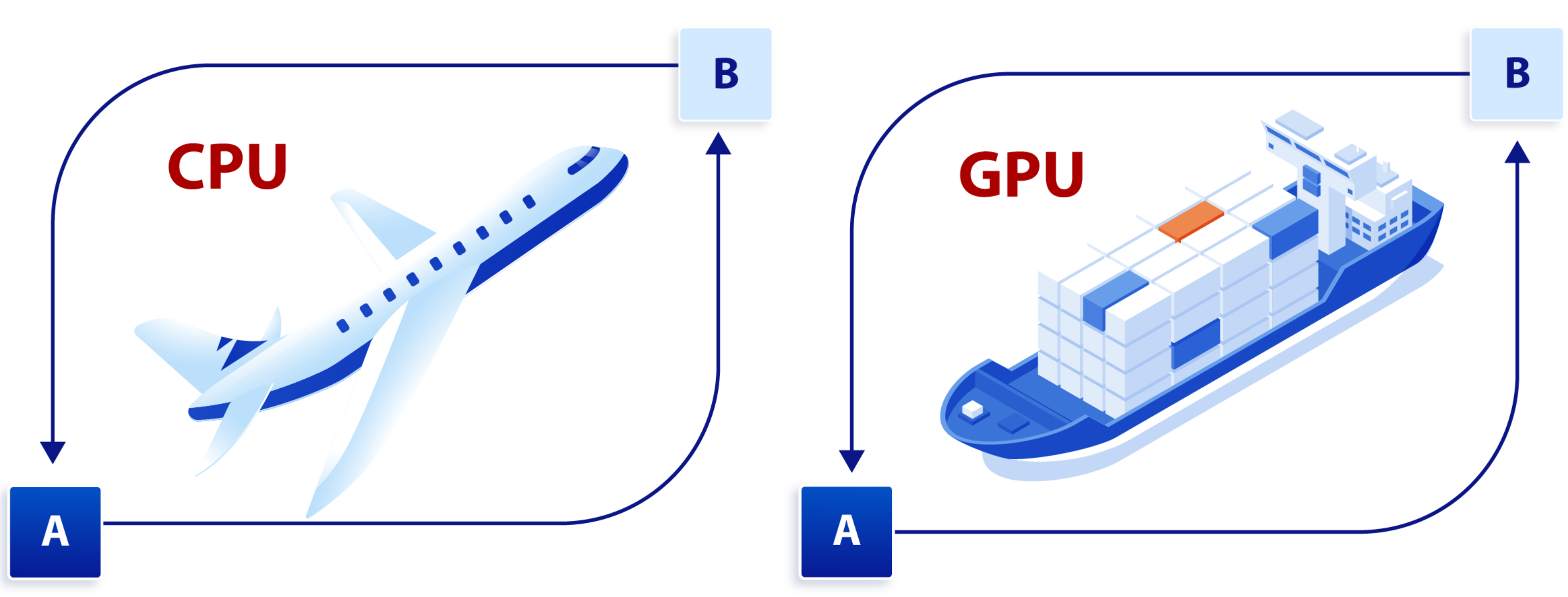
CPU vs GPU:不仅仅是一字之差
当今科学技术的飞速发展,社会已经迈入了信息时代的智能化阶段。人脸识别、智能客服、个性化推荐等应用已经深入到日常生活的各个方面。这些看得见的应用背后,是看不见的算力在默默地支撑着。在满足这些高算力需求的过程中,CPU 和 GPU 作为计算…

对标开源3D建模软件blender,基于web提供元宇宙3D建模能力的dtns.network德塔世界是否更胜一筹?
对标开源3D建模软件blender,基于web提供元宇宙3D建模能力的dtns.network德塔世界是否更胜一筹? blender是一款优秀的3D建模开源软件,拥有免费开源、功能强大、渲染速度优秀的优点。而开源的dtns.network德塔世界,亦是专业级的元宇…
提升程序运行速度-计算加速的20种方法
下面是计算加速的20种方法以及对应的优缺点和应用场景的列表:
1. 并行计算: - 优点:可以同步执行多个任务,提高计算速度。 - 缺点:需要额外的硬件支持,并且某些任务可能无法并行化。 - 应用场景࿱…

史上最强 PyTorch 2.2 GPU 版最新安装教程
一 深度学习主机
1.1 配置
先附上电脑配置图,如下: 利用公司的办公电脑对配置进行升级改造完成。除了显卡和电源,其他硬件都是公司电脑原装。
1.2 显卡
有钱直接上 RTX4090,也不能复用公司的电脑,其他配置跟不上。…
报错-mmdet/cuda编译报错: fatal error: THC/THC.h: No such file or directory
目录 现象原因解决方法 现象
当执行 python setup.py develop ,有如下报错: fatal error: THC/THC.h: No such file or directory原因
1.11版本后,Pytorch中的THC/THC 命名空间已失效,apex 也已将其删除,但是其中的函…
借助GPU算力编译Android
借助GPU算力编译Android
借助GPU编译Android代码的意义在于提高编译的效率和速度。传统的CPU编译方式在处理大量代码时可能会遇到性能瓶颈,而GPU编译利用了显卡的并行计算能力,可以同时处理多个任务,加快编译过程。通过利用GPU的并行计算能力,可以将编译过程中的多个任务分…
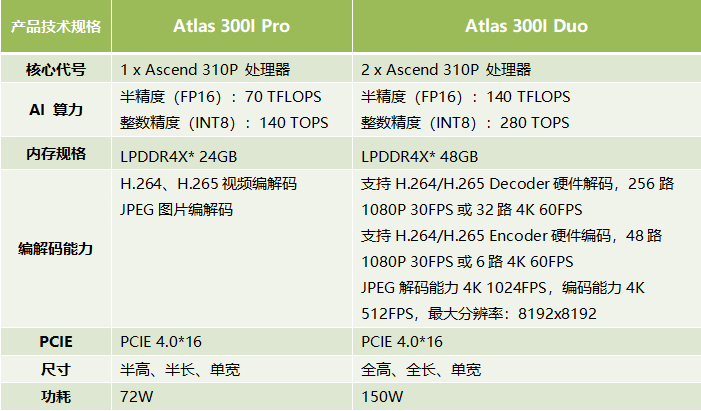
华为Atlas的迭代关系、性能特点与典型应用场景
衔接上文,本篇主要讲解华为Atlas训练卡的迭代关系。以及迭代后的训练卡性能特点与典型应用场景。 Atlas 300T A2 训练卡的迭代关系为Atlas 300T Pro升级到Atlas 300T A2。相比之下,Atlas 300T A2 性能特点:
○ 高度集成
AI算力、通用算力、…
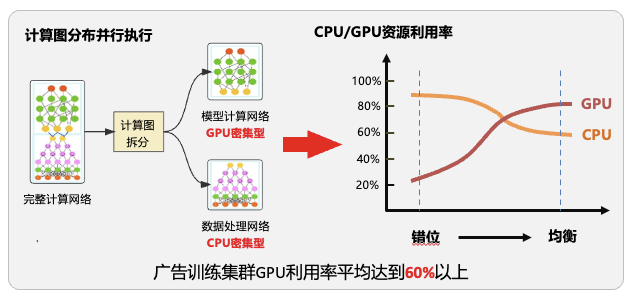
稀疏场景高性能训练方案演变|京东广告算法架构体系最佳实践
近年来,推荐场域为提升模型的表达能力和计算能力,模型规模和计算复杂度大幅增加,同时,高规格硬件资源为模型迭代、算法优化带来了更大的机遇和挑战。为了应对模型规模和算力升级带来的存储、IO和计算挑战,京东零售广告…
用Bing绘制「V我50」漫画;GPT-5业内交流笔记;LLM大佬的跳槽建议;Stable Diffusion生态全盘点第一课 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 美国升级AI芯片出口禁令,13家中国GPU企业被列入实体清单 nytimes.com/2023/10/05/technology/chip-makers-china-lobbying…
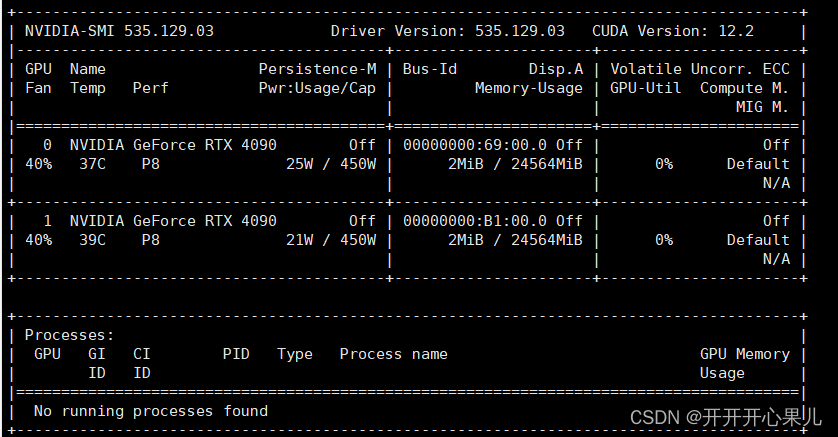
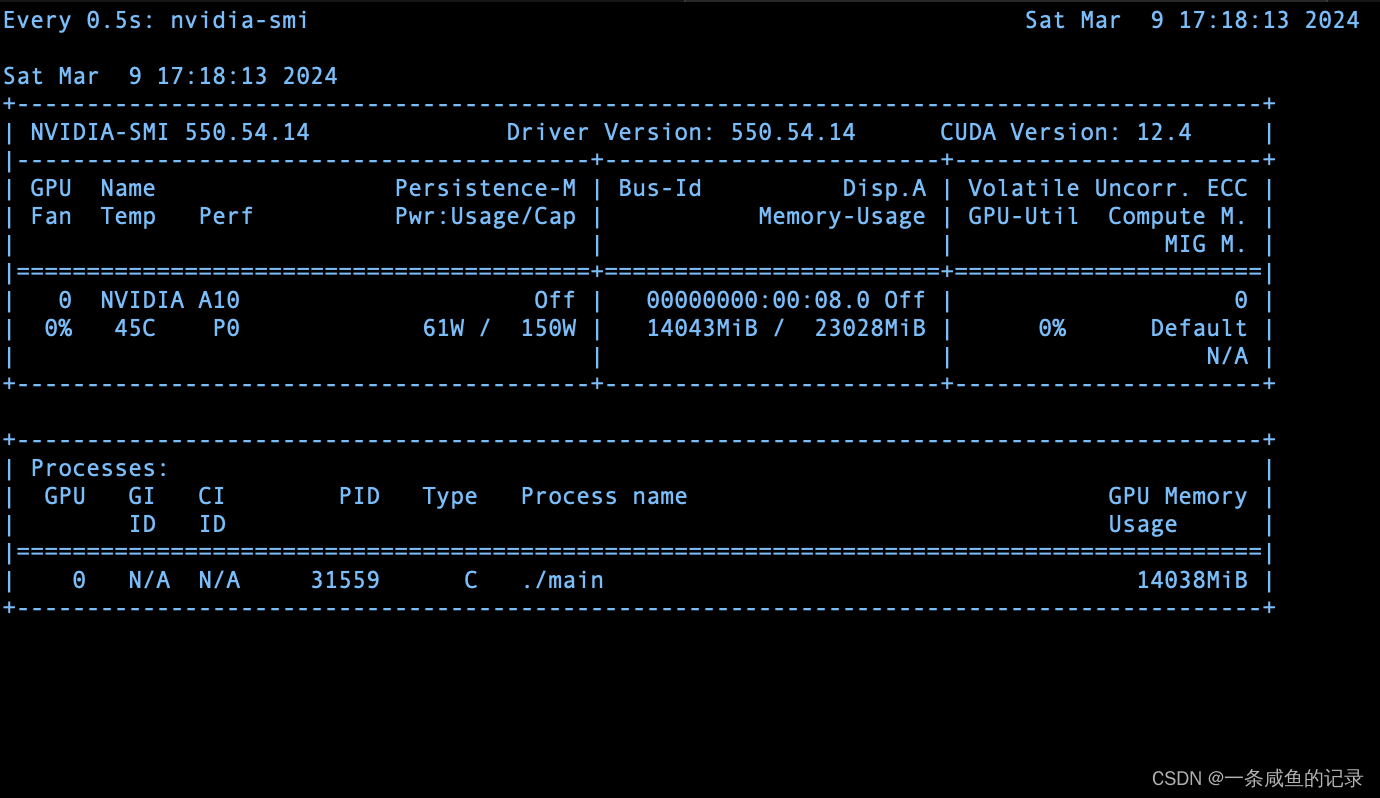
nvidia-smi查看无进程,但GPU占用率100%问题解决
问题:nvidia-smi查看无进程,但GPU占用率100%问题解决 原因:记住记住记住CtrlZ是把当前运行程序挂起,并不是终止运行,终止用CtrlC,前段时间跑代码测性能和看部分结果一直用的CtrlZ,导致程序都处于挂起状态&…

京津冀协同发展:北京·光子1号金融算力中心——智能科技新高地
京津冀协同发展是党中央在新的历史条件下提出的一项重大国家战略,对于全面推进“五位一体”总体布局,以中国式现代化全面推进强国建设、民族复兴伟业,具有重大现实意义和深远历史意义。随着京津冀协同发展战略的深入推进,区域一体…
硬件加速器及其深度神经网络模型的性能指标理解
前言: 现如今,深度神经网络模型和硬件加速器,如GPU、TPU等的关系可谓是“不分彼此”,随着模型参数的增加,硬件加速器成为了训练、推理深度神经网络不可或缺的一个工具,而近年来硬件加速器的发展也得益于加速…
【个人开发】llama2部署实践(二)——基于GPU部署踩坑
折腾了一整天,踩了GPU加速的一堆坑,记录一下。
1.GPU加速方式
上篇已经写了llama2部署的大概流程:【【个人开发】llama2部署实践(一)】——基于CPU部署
针对llama.cpp文件内容,仅需再make的时候带上参数…

喜报 | 热烈祝贺思腾合力成功挂牌天津OTC专精特新板
近日,天津区域性股权市场企业挂牌上市成果发布会于2023中国民营企业投融资洽谈会上成功举行。在会上公布,思腾合力成功挂牌天津OTC“专精特新”板。 本次活动由北交所(新三板)天津基地、天津证监局、市发改委,天津滨海…
AUTODL云服务器使用大致步骤(适合本人版)
(一)在官网上创建一个服务器
(二)远程连接指令: 改为: (三)连接后,可在中进行代码运行 输入一些指令 python ......
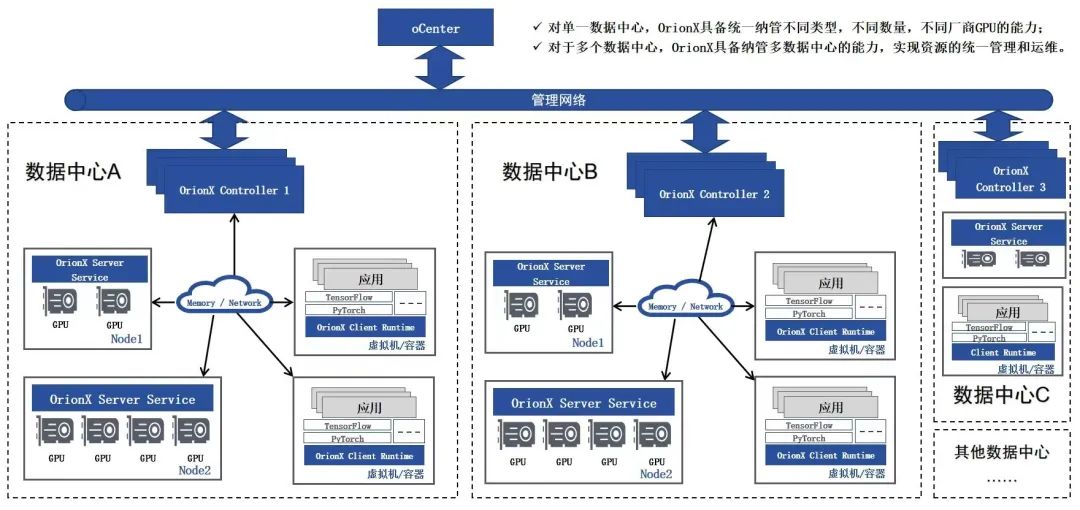
盘活存量GPU资源 破局高校算力不足窘境
“凭啥做大模型的优先分配算力?人家1个人4块A800,我们10个人用2块3090!这日子没法过了!”听着团队成员们的吐槽,某国内顶尖高校非大模型团队带队的博士老W也颇为无奈:“我们虽然不是做大模型的,…
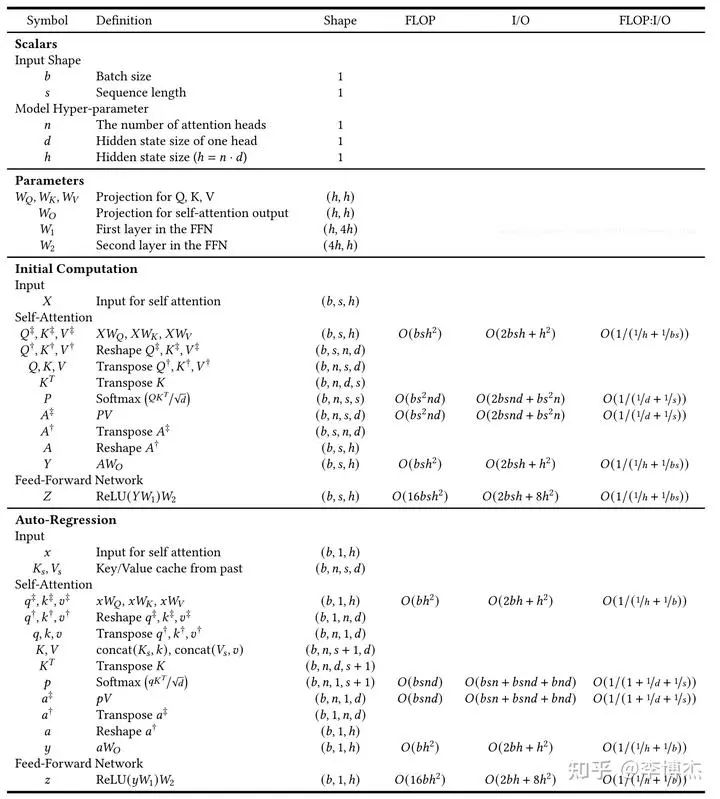
大模型训练为什么用A100不用4090
这是一个好问题。先说结论,大模型的训练用 4090 是不行的,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
事实上&#x…
在 WSL2 中使用 NVIDIA Docker 进行全栈开发和深度学习 TensorFlow pytorch GPU 加速
WSL2使用NVIDIA Docker进行全栈开发和深度学习
1. 前置条件
1.1. 安装系统
Windows 10 版本 2004 及更高版本(内部版本 19041 及更高版本)或 Windows 11
跳过
1.2. 处理好网络环境
安装过程中需要访问国际网络,自行处理好。建议开启 tu…

pytorch12:GPU加速模型训练
目录 1、CPU与GPU2、数据迁移至GPU2.1 to函数使用方法 3、torch.cuda常用方法4、多GPU并行运算4.1 torch.nn.DataParallel4.2 torch.distributed加速并行训练 5、gpu总结 往期回顾 pytorch01:概念、张量操作、线性回归与逻辑回归 pytorch02:数据读取Data…
和鲸ModelWhale平台与海光人工智能加速卡系列完成适配认证,夯实 AI 应用核心底座
AIGC 浪潮席卷,以大模型为代表的人工智能发展呈现出技术创新快、应用渗透强、国际竞争激烈等特点。创新为本,落地为王,技术的快速发展与大规模训练需求的背后,是对平台化基础设施与 AI 算力的更高要求。在此全球 AI 产业竞争的风口…
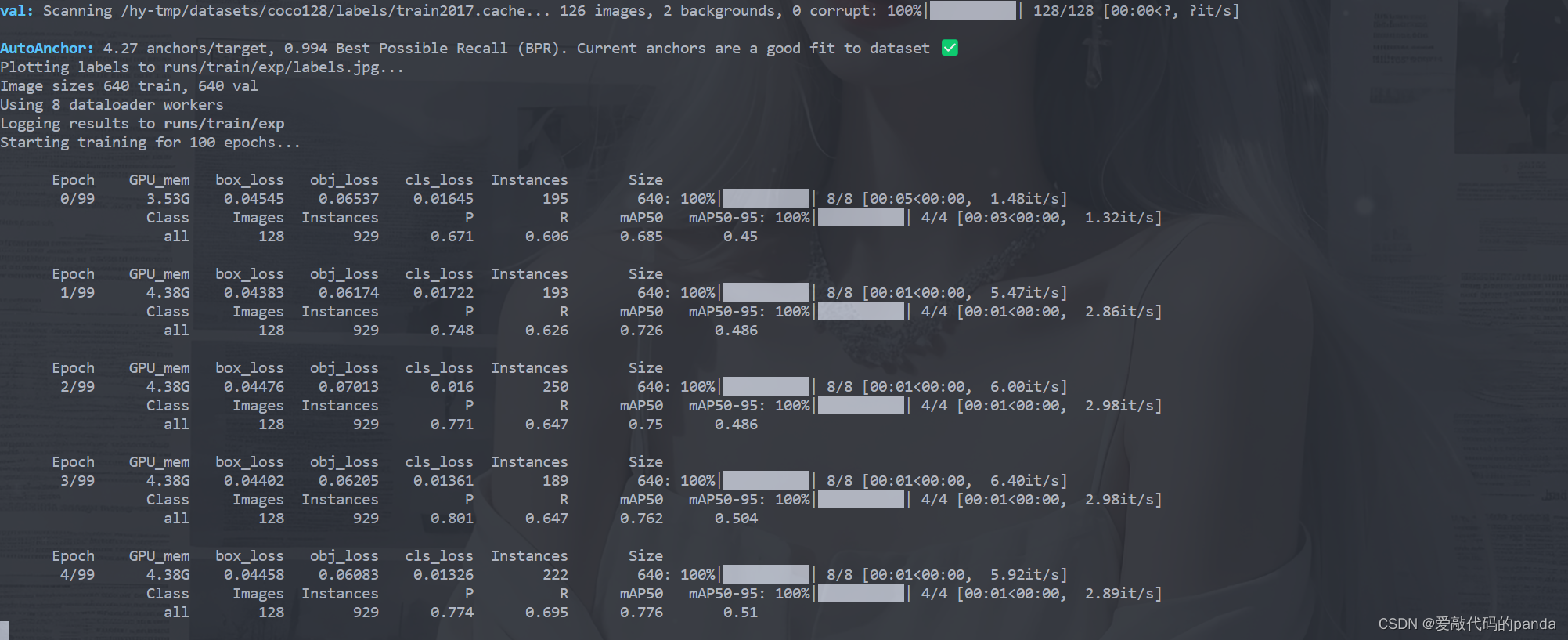
GPU云服务器使用教程、运行YOLOV5项目并连接到本地VSCode(Pycharm)
编程如画,我是panda! 之前已经教过大家如何在自己的电脑中配置Pytorch深度学习环境,但是有些小伙伴没有英伟达的GPU,所以用CPU的话训练模型会比较慢,所以这次出一期使用GPU云服务器的教程。 码字不易,如果对…
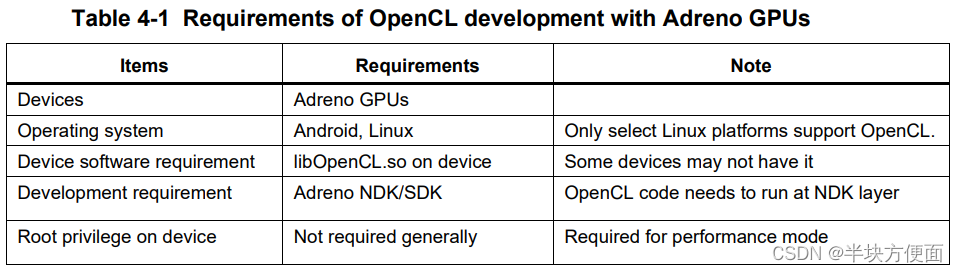
Chart 3 Adreno OpenCL 应用程序开发
文章目录 前言4.1 Android上进行OpenCL应用程序开发4.2 Adreno OpenCL SDK 和 Adreno OpenCL 机器学习 SDK4.3 调试工具和技巧 前言
本章主要介绍如何 debug Adreno OpenCL应用程序 4.1 Android上进行OpenCL应用程序开发
Adreno GPU 主要在 Android 操作系统和部分 Linux 系统…

开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势未来发展方向
开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势&未来发展方向 写在最前面一、开源与闭源:定义与历史背景开源和闭源的定义开源大模型:社区驱动的创新 二、开源和闭源的优劣势比较开源大模型(瓶颈)数据&…

transfomer的位置编码
什么是位置编码
在transformer的encoder和decoder的输入层中,使用了Positional Encoding,使得最终的输入满足: input_embeddingpositional_encoding 这里,input_embedding的shape为[n,b,embed_dim],positional_encoding和input_…
方法-进程已经杀死但是显存还未释放怎么办(ubuntu)
本专栏为深度学习的一些技巧,方法和实验测试,偏向于实际应用,后续不断更新,感兴趣童鞋可关,方便后续推送
现象
训练程序ctrlc后,依然显示显存占用 nvidia-smi Mon Dec 6 14:26:33 2021 ---------------------------------------------------------------------------- | NVID…